- Published on
AI 智能体高可靠设计模式:并行查询扩展
- Authors

- Name
- 俞凡
本系列介绍增强现代智能体系统可靠性的设计模式,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。本系列一共 14 篇文章,这是第 10 篇。原文:Building the 14 Key Pillars of Agentic AI
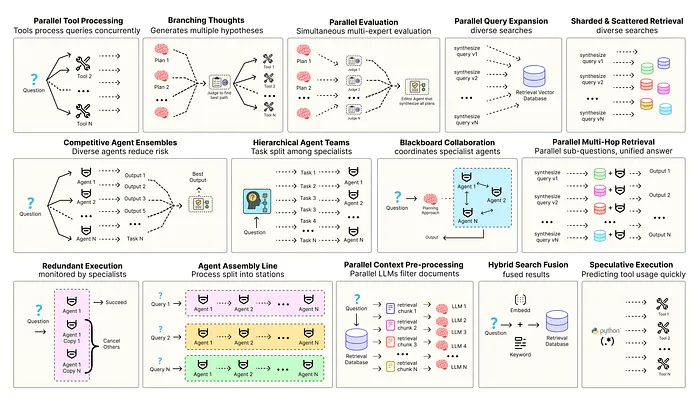
优化智能体解决方案需要软件工程确保组件协调、并行运行并与系统高效交互。例如预测执行,会尝试处理可预测查询以降低时延,或者进行冗余执行,即对同一智能体重复执行多次以防单点故障。其他增强现代智能体系统可靠性的模式包括:
- 并行工具:智能体同时执行独立 API 调用以隐藏 I/O 时延。
- 层级智能体:管理者将任务拆分为由执行智能体处理的小步骤。
- 竞争性智能体组合:多个智能体提出答案,系统选出最佳。
- 冗余执行:即两个或多个智能体解决同一任务以检测错误并提高可靠性。
- 并行检索和混合检索:多种检索策略协同运行以提升上下文质量。
- 多跳检索:智能体通过迭代检索步骤收集更深入、更相关的信息。
还有很多其他模式。
本系列将实现最常用智能体模式背后的基础概念,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。
所有理论和代码都在 GitHub 仓库里:🤖 Agentic Parallelism: A Practical Guide 🚀
代码库组织如下:
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb
并行查询扩展以最大化召回率
在自主式 RAG 模式中最常见的问题是词汇不匹配,因为用户很少知道专业知识库中使用的精确关键词或术语。
像“如何使模型更大更快”这样的简单查询可能无法检索到包含“混合专家(Mixture of Experts)”和“快速注意力(FlashAttention)”等技术术语的文档。
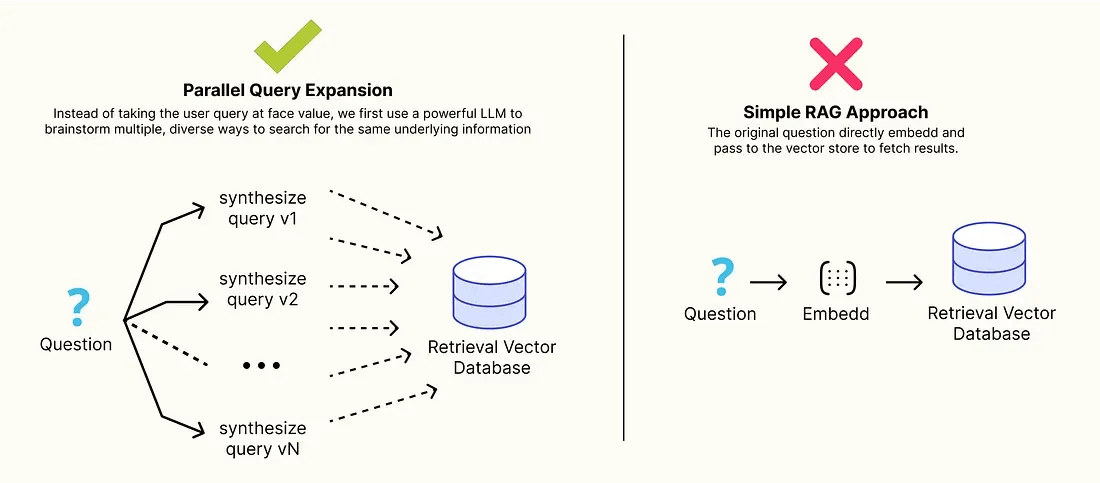
并行查询扩展(Parallel Query Expansion) 就是为解决这种问题提出的架构解决方案,不同于直接使用用户输入进行查询,而是首先通过 LLM 来构思多种类、多样化的搜索方式,以获取相同的底层信息。这个“预检索”步骤可以并行生成一系列搜索查询,例如:
- 回答该问题的假设性文档(HyDE,hypothetical document)。
- 分解出若干子问题。
- 一组提取的关键词和实体。
通过并行执行所有这些查询并融合结果,可以显著提高检索步骤的召回率,用不同术语确保找到所有相关证据。
接下来我们用基于这种模式构建并和简单 RAG 系统进行比较,以证明其产生的最终答案更加完整和准确。
首先定义构建查询输出的 Pydantic 模型,从而使得 LLM 可以在一次可靠调用中生成所有期望的查询变体。
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
class ExpandedQueries(BaseModel):
"""Pydantic 模型定义了一组不同的扩展查询,以提高检索召回率"""
# 生成的假设文档段落,在语义上与可能的答案相似
hypothetical_document: str = Field(description="A generated, paragraph-length hypothetical document that directly answers the user's question, which will be used for semantic search.", alias="hyde_query")
# 将原始查询分解为更小、更具体的问题列表
sub_questions: List[str] = Field(description="A list of 2-3 smaller, more specific questions that break down the original query.")
# 用于精确词法搜索的核心关键字和实体列表
keywords: List[str] = Field(description="A list of 3-5 core keywords and entities extracted from the user's query.")
通过指示 LLM 填充这个结构化对象,从而确保得到多样化的搜索策略组合,包括语义策略(hypothetical_document)、分解策略(sub_questions)和词汇策略(keywords),所有这些都来自一次高效 LLM 调用。
接下来构建一个 LangGraph 图的 RAG 系统,第一个节点就是查询扩展代理。
from typing import TypedDict, List, Optional
from langchain_core.documents import Document
class RAGGraphState(TypedDict):
original_question: str
expanded_queries: Optional[ExpandedQueries]
retrieved_docs: List[Document]
final_answer: str
# 节点 1: 查询扩展代理
query_expansion_prompt = ChatPromptTemplate.from_messages([
("system", "You are a query expansion specialist. Your goal is to transform a user's question into a diverse set of search queries to maximize retrieval recall. Generate a hypothetical document, sub-questions, and keywords."),
("human", "Please expand the following question: {question}")
])
# 该链将提示符通过管道链接到 LLM,并基于 Pydantic 模型构建其输出
query_expansion_chain = query_expansion_prompt | llm.with_structured_output(ExpandedQueries)
def query_expansion_node(state: RAGGraphState):
"""图中的第一个节点:获取原始问题并生成一组扩展查询"""
print("--- [Expander] Generating parallel queries... ---")
expanded_queries = query_expansion_chain.invoke({"question": state['original_question']})
return {"expanded_queries": expanded_queries}
query_expansion_node 是高级检索过程中的"思考"步骤,该节点接收用户原始查询,不立即进行搜索,而是先用 LLM 来头脑风暴出一套更强大的查询集,为更全面的搜索做好准备。
下一个节点将并行执行所有这些生成的查询。
from concurrent.futures import ThreadPoolExecutor
def retrieval_node(state: RAGGraphState):
"""第二个节点:接受且并行执行扩展查询"""
print("--- [Retriever] Executing parallel searches... ---")
# 创建一个包含所有要执行的查询列表
all_queries = []
expanded = state['expanded_queries']
all_queries.append(expanded.hypothetical_document)
all_queries.extend(expanded.sub_questions)
all_queries.extend(expanded.keywords)
all_docs = []
# 用 ThreadPoolExecutor 并发运行所有检索器调用
with ThreadPoolExecutor(max_workers=5) as executor:
results = executor.map(retriever.invoke, all_queries)
for docs in results:
all_docs.extend(docs)
# 最后一步是对检索到的文档删除重复数据,以创建干净、唯一的上下文
unique_docs = {doc.page_content: doc for doc in all_docs}.values()
print(f"--- [Retriever] Found {len(unique_docs)} unique documents from {len(all_queries)} queries. ---")
return {"retrieved_docs": list(unique_docs)}
retrieval_node 是执行并行查询的节点,核心是 ThreadPoolExecutor 和 executor.map,将 7-9 个扩展查询列表同时分派到向量存储中。这种"分散-收集"的方法确保我们能够获得所有搜索视角的综合效益,而不会增加线性时延。
最后组装图,按顺序连接扩展、检索并最终生成节点。
from langgraph.graph import StateGraph, END
workflow = StateGraph(RAGGraphState)
# 将节点加入图
workflow.add_node("expand_queries", query_expansion_node)
workflow.add_node("retrieve_docs", retrieval_node)
workflow.add_node("generate_answer", generation_node)
# 定义线性工作流
workflow.set_entry_point("expand_queries")
workflow.add_edge("expand_queries", "retrieve_docs")
workflow.add_edge("retrieve_docs", "generate_answer")
workflow.add_edge("generate_answer", END)

现在进行最终对比分析,向简单 RAG 和高级 RAG 系统提供同一个模糊查询,比较检索到的上下文质量和最终答案的质量。
# 用户查询使用一般术语(“big and fast”)而不是知识库中的技术术语
user_query = "How do modern AI systems get so big and fast at the same time? I've heard about attention but I'm not sure how it's optimized."
# --- 执行简单 RAG 系统 ---
print("--- [SIMPLE RAG] Retrieving documents...")
# 拦截检索步骤以检查简单系统找到的内容
simple_retrieved_docs = retriever.invoke(user_query)
print(f"--- [SIMPLE RAG] Documents Retrieved: {len(simple_retrieved_docs)}")
simple_rag_answer = simple_rag_chain.invoke(user_query)
# --- 执行高级 RAG 系统 ---
# --- 最终分析 ---
print("\n" + "="*60)
print(" RETRIEVED DOCUMENTS COMPARISON")
print("="*60)
print(f"\n--- Simple RAG Retrieved {len(simple_retrieved_docs)} document(s) ---")
for i, doc in enumerate(simple_retrieved_docs):
print(f"{i+1}. {doc.page_content}")
print(f"\n--- Advanced RAG Retrieved {len(advanced_rag_result['retrieved_docs'])} document(s) ---")
for i, doc in enumerate(advanced_rag_result['retrieved_docs']):
print(f"{i+1}. {doc.page_content}")
print("\n" + "="*60)
print(" ACCURACY & QUALITY ANALYSIS")
输出结果为……
#### 输出 ####
============================================================
RETRIEVED DOCUMENTS COMPARISON
============================================================
--- Simple RAG Retrieved 1 document(s) ---
1. **Multi-headed Attention Mechanism**: The core component of the Transformer architecture is the multi-headed self-attention mechanism...
--- Advanced RAG Retrieved 3 document(s) ---
1. **FlashAttention Optimization**: ...FlashAttention is an I/O-aware algorithm that reorders the computation to reduce the number of read/write operations...
2. **Mixture of Experts (MoE) Layers**: ...a router network dynamically selects a small subset of 'expert' sub-networks to process each input token...
3. **Multi-headed Attention Mechanism**: The core component of the Transformer architecture...
分析得出了一些结论……
- 高级系统之所以成功,是因为
query_expansion_node弥合了语义鸿沟。其假设文档和目标子查询引入了缺失的技术术语Mixture of Experts、FlashAttention、scaling、optimization,从而使得检索到额外的关键文档成为可能。 - 检索到的文档召回率有所提升。通过捕获所有三个相关文档,高级系统提供了完整上下文,使生成器能够产出全面、技术准确且质量更高的答案。