- Published on
AI 智能体 8 层架构:生产级系统构建指南
- Authors

- Name
- 俞凡
本文深入探讨了 AI 智能体的 8 层架构,提供了构建生产级系统的指南。原文:The 8-Layer Architecture of Agentic AI: A Systems Architect's Guide to Building Production-Grade…
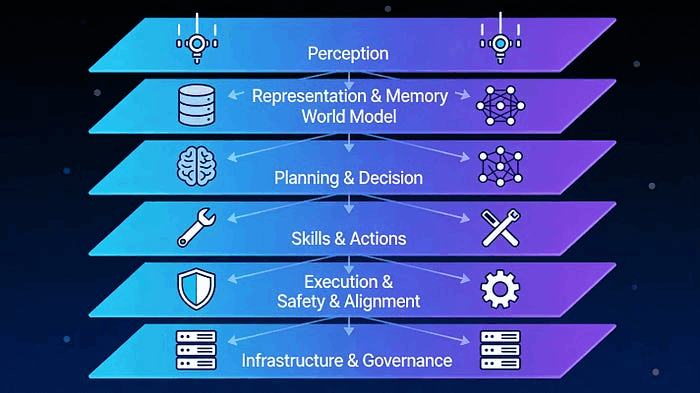
AI 智能体(Agentic AI)革命的关键不在更好的提示词,而在于系统化的架构设计。随着企业竞相部署能够自主感知、推理、规划和行动的 AI 智能体(AI Agent),真正的挑战已经从"我们能构建吗?"转变为"我们能正确构建吗?"
数据很能说明问题。全球智能体 AI 市场从 2024 年的 6140 万美元激增到 2032 年预计将达到 2.6 亿美元,复合年增长率(CAGR)高达 20.1%。Gartner 预测,到 2026 年底,40% 的企业应用将嵌入 AI 智能体,而 2025 年这一比例还不到 5%。但问题在于:80% 的组织表示,已经投入生产的 AI 智能体带来了可衡量的投资回报率(ROI),但 46% 的组织将与现有系统的集成列为主要障碍。
解决方案是什么?不要再把智能体视为单一的大语言模型(LLM)包装,而应将其视为具有清晰架构边界的分布式系统。
本文将详细剖析区分生产级智能体系统与脆弱原型的 8 层架构。无论是构建交易算法、企业自动化还是自主研究助手,这个框架都能提供结构化方法来管理复杂性、实施治理,并交付能够在真实负载下不崩溃的系统。
为什么大多数智能体 AI 项目在扩展时会失败
在深入探讨各层之前,我们先承认一个显而易见的问题。大多数智能体实现遇到的瓶颈,不是因为模型能力不足,而是因为缺少基础设施。
典型失败模式如下:团队构建了一个给利益相关者留下深刻印象的概念验证智能体。该智能体能够回答问题、调用 API,甚至将多个步骤链接在一起。这算成功了,对吗?然后推送到生产环境,遇到了级联故障 —— 幻觉行为、不可预测的成本、安全违规、无法调试的错误,以及完全没有审计追踪。
为什么会这样?因为他们构建的是一个有工具访问权限的聊天机器人,而不是架构化系统。
生产级智能体需要与任何分布式系统相同的严谨性:模块化、可观测性、容错性、安全边界和治理框架。8 层架构正好提供了这种结构。
第 1 层:感知/输入层
职责:收集、标准化和预处理来自外部世界的原始信号(文本、音频、图像、API、传感器、数据库事件),将其转换为上游层可以可靠消费的统一观测对象。
输入输出:
- 输入:原始数据流(HTTP/webhook、Kafka、S3 文件、摄像头流、IoT 传感器)
- 输出:标准化观测事件(JSON 模式)、特征向量、时间序列数据
为什么重要:智能体的质量取决于其输入。垃圾进,垃圾出——而且是在自主规模下。感知层充当你的事件网关和模式强制执行者。没有它,上游层会浪费 token 处理格式错误的数据,因格式不一致而错过关键事件,更糟糕的是,会对溜进来的对抗性输入采取行动。
实现模式:
- 统一事件模式:使用 JSON Schema 或 Protobuf 等工具定义规范观测模型。每个输入(无论是来自 webhook、文件上传还是流传感器)都会转换为这种标准格式。
- 多模态预处理:对于复杂输入(图像、音频、PDF),运行专门的预处理:文档使用 OCR,语音使用 ASR,图像使用 CLIP 嵌入向量。输出标准化语义表示。
- 边缘过滤与验证:在摄入阶段实施内容过滤,在昂贵的 LLM 调用之前阻止恶意或超出范围的输入。速率限制、模式验证和个人可识别信息(PII)检测都在这里完成。
- 延迟绑定与提前绑定:决定是同步处理事件(即时响应,延迟更高)还是异步处理事件(解耦摄入与处理,吞吐量更高)。
安全与可观测性:
- 带来源归属和时间戳的输入审计日志
- 输入格式演化时的模式漂移检测
- 格式错误事件的死信队列
- 下游层过载时的反压机制
实际考虑:一位金融服务客户仅仅通过在感知层实施严格的模式验证,就将智能体错误减少了 40%。他们之前的设置允许松散类型的 API 负载到达推理层,导致下游不可预测的故障。
第 2 层:表示与记忆层
职责:将观测转换为可查询、可复用的表示(嵌入向量、知识片段、情景记忆)并管理记忆生命周期(缓存、总结、修剪、删除)。
输入输出:
- 输入:观测、模型输出、人工注释
- 输出:向量索引、检索 API、记忆元数据
这就是检索增强生成(RAG)所在的层次。但将其视为"只是向量搜索"是一个错误。生产级记忆系统需要分层存储、智能遗忘和跨会话连续性。
实现模式:
- 分层记忆架构:
- 短期(工作记忆):Redis 或内存缓存,用于存储当前会话上下文(最近 N 轮对话、活跃任务状态)
- 长期(情景记忆):向量数据库(Pinecone、Qdrant、Weaviate),用于对过去交互进行语义检索
- 语义记忆:知识图谱或结构化数据库,用于存储事实、关系、实体属性
- 向量数据库选择:
- Pinecone:托管式低延迟近似最近邻(ANN)搜索,内置推理(嵌入向量+搜索+重排序在一次 API 调用中完成)
- Qdrant:开源,强大的元数据过滤,适用于带结构化查询的复杂检索增强生成
- Weaviate:内置机器学习模型,GraphQL 接口,非常适合多模态数据
- MongoDB Atlas Vector Search:当你已经使用 MongoDB 并想要统一文档+向量存储时最佳选择
- 记忆整合与压缩:
- 使用基于 LLM 的摘要来压缩对话历史(例如,每 10 轮对话进行总结并存储)
- 实施分层衰减:近期记忆、较早记忆、压缩或聚合记忆
- 应用聚类识别重复模式并创建语义原型
- 战略性遗忘:
- 并非所有数据都值得永久存储。实施 TTL(生存时间)策略
- 使用相关性评分修剪低价值记忆
- 通过版本化删除和审计追踪支持 GDPR"被遗忘权"
安全与可观测性:
- 记忆访问控制(基于角色的访问控制(RBAC)):谁可以读取/写入哪些记忆
- 记忆版本控制和更改日志,以支持审计
- 隐私保护嵌入向量(差分隐私、联邦学习)
- 成本追踪:向量数据库存储和查询成本在规模下会爆炸
架构深度探讨:在 2026 年 1 月,高级记忆系统使用图增强检索增强生成。与平面向量搜索不同,可以维护情景图,其中节点表示记忆,边捕获时间、因果或语义关系。从而可以支持多跳推理:"当用户上个月问 X 时,我们推荐了 Y,但失败了。这次试试 Z。"
第 3 层:世界模型/知识推理层
职责:维护环境、任务上下文、实体和关系的抽象、可更新模型。支持因果推理、状态估计、约束检查和假设生成。
输入输出:
- 输入:表示/记忆、外部知识源(知识图谱、规则引擎)
- 输出:当前世界状态、预测、约束集合、置信度估计
把这想象成你的智能体的心智模型。它不只是"发生了什么"(那是记忆),而是"现在什么是真的"和"接下来可能发生什么"。
为什么大多数智能体跳过这一层——为什么这是个错误:许多智能体化系统直接从记忆跳到规划。这对于简单任务有效,但在以下情况会崩溃:
- 智能体需要在多次交互中推理实体状态
- 行动存在依赖关系(如果信用卡被拒绝,就无法预订航班)
- 合规规则限制了允许的操作(GDPR、SOX、内部政策)
世界模型层将这些约束提升为一等公民。
实现模式:
- 知识图谱作为世界状态:
- 实体:用户、账户、订单、工单、产品
- 关系:拥有、依赖、冲突、批准
- 属性:状态、时间戳、置信度、来源
- 更新:随着事件发生,图谱演化(例如,"订单 #123 状态:已发货")
- 约束推理:
- 将业务规则、监管要求和服务水平协议(SLA)编码为逻辑约束
- 在执行计划之前,根据约束进行验证
- 示例:"未经二次验证(2FA)批准,不得转账超过 1 万美元"
- 时间状态追踪:
- 不仅追踪当前状态,还追踪状态历史(审计追踪、回滚、调试)
- 实施版本化状态快照(检查点)
- 概率推理:
- 并非所有世界状态都是确定的。用置信度分数标记实体
- 当新观测到达时,使用贝叶斯更新
- 向规划层呈现不确定性("80% 置信用户偏好选项 A")
安全与可观测性:
- 世界模型来源:哪些观测/规则导致了当前状态
- 异常检测:当模型与实际情况偏离时标记(例如,预测库存与实际不匹配)
- 可解释性:生成"推理轨迹",显示模型如何得出结论
实际示例:医疗保健智能体使用世界模型跟踪患者状态(当前药物、过敏史、近期生命体征)。在规划治疗建议时,会检查约束(药物相互作用、剂量限制)。如果提议的行动违反约束,规划层必须生成替代方案。
第 4 层:规划与决策层
职责:给定目标、当前世界状态和约束,生成高层计划(任务分解、行动序列、替代策略)并附带置信度估计。
输入输出:
- 输入:目标、世界状态、策略偏好、约束
- 输出:计划(行动序列/子目标树)、评估分数、候选替代方案
这就是自主性发生的地方。规划层决定"如何实现目标",而不仅仅是"下一步做什么"。
为什么分层规划很重要:扁平的单步智能体在长周期任务上举步维艰。分层任务网络(HTN)将复杂目标递归分解为可管理的子任务,直到达到原始动作。
实现模式:
- 分层任务网络(HTN):
- 定义分解方法:"准备餐点" → ["选择食谱", "收集食材", "烹饪", "上菜"]
- 每个子任务进一步分解,直到达到可执行原语
- 分层任务网络规划器使用领域知识指导分解(快速、确定)
- LLM 增强的分层任务网络:当领域知识不完整时,查询 LLM 获取合理分解
- 面向目标的规划:
- 从高层意图(声明性目标)开始,而不是过程步骤
- 使用反向链式推理:"要实现 X,我需要 Y 和 Z;要实现 Y,我需要 A 和 B。"
- 支持灵活执行:到达同一目标有多条路径
- 多计划生成与评估:
- 不要只生成一个计划。生成 3-5 个带权衡的替代方案(快速 vs 便宜 vs 安全)
- 使用评论家/评估器在多个维度(成本、延迟、风险、合规性)上对计划评分
- 将前 N 个计划呈现给编排层进行选择(对于高风险决策需要人工批准)
- 感知约束的规划:
- 计划必须满足前置条件,尊重资源限制,避免违反政策
- 与第 3 层(世界模型)集成进行实时约束检查
- 如果无法满足约束,升级给人工或生成"计划不可行"信号
- 重新规划与恢复:
- 计划会失败。执行遇到错误。规划层必须支持动态重新规划
- 实施反馈循环:执行报告进度,如果检测到偏差,规划会进行调整
安全与可观测性:
- 计划批准日志:跟踪哪些计划被生成、选择、批准、拒绝
- 计划验证:执行前的静态分析(前置条件/后置条件检查)
- 干运行模拟:在提交实际操作之前在沙箱中测试计划
- 风险评分:用风险级别(低/中/高)标记计划,对高风险计划实施批准门控
实际实现:使用 LLM 进行规划是可行的,但需要护栏。现代系统将结构化领域的符号规划(HTN、PDDL)与开放式任务的 LLM 规划相结合。示例:LangGraph 的分层智能体使用基于 LLM 的规划器智能体分解任务,然后委托给专门的执行器智能体(工具调用)。
第 5 层:技能/行动层
职责:封装可复用的"技能"或原子动作原语(API 调用、数据库事务、文件操作、机器人命令),并提供清晰的契约(输入、输出、副作用、失败模式)。
输入输出:
- 输入:来自规划层的参数化动作请求
- 输出:执行结果(成功/失败、返回值、副作用)
把这想象成你的智能体的工具箱。每个技能都是一个定义良好接口的函数,实现为微服务、FaaS 函数或 API 包装器。
为什么技能需要契约:当智能体动态调用工具时,你需要关于行为的硬性保证。如果 API 超时会发生什么?如果使用无效参数调用会怎样?它会修改状态,如果修改了,可以回滚吗?
没有契约,你会得到不可预测的智能体行为和无法调试的问题。
实现模式:
- 动作模式定义:
- 每个技能都有一个 JSON 模式,指定输入、输出、前置条件和效果
- 示例:
transfer_funds(from_account, to_account, amount) → {success: bool, transaction_id: str} - 模式包含约束:
amount > 0,from_account != to_account
- 幂等性与补偿:
- 幂等动作:调用两次产生相同结果(安全重试)
- 补偿事务:如果动作在执行中途失败,运行回滚(Saga 模式)
- 示例:如果"信用卡收费"成功但"发货订单"失败,运行"信用卡退款"
- 沙箱执行:
- 高风险动作(数据删除、金融交易)在隔离环境中运行
- 执行前需要明确批准(人在回路门控)
- 实施预览模式:在提交之前显示会发生什么
- 工具发现与选择:
- 智能体需要动态发现可用技能(特别是在大型工具集中)
- 对工具描述使用语义搜索(嵌入工具文档,检索与任务相关的工具)
- 基于 LLM 的路由:给定用户意图,选择合适的工具
- 最小权限与权限:
- 每个技能只拥有它需要的权限(数据库:只读 vs 读写)
- 使用具有范围凭证的服务账户(不共享管理员密钥)
- 审计所有工具调用,记录完整参数
安全与可观测性:
- 动作审计追踪:谁调用了什么工具,何时,使用什么参数,结果是什么
- 每个工具的速率限制(防止失控循环)
- 每个动作的成本追踪(某些工具很昂贵 —— LLM 调用、云 API)
- 失败分析:哪些工具最常失败,为什么,如何优雅处理
实际模式:领先的实现使用模型上下文协议(MCP)或智能体间协议(A2A)来标准化工具通信。这使得技能可以在不同智能体框架(LangGraph、CrewAI、AutoGen)之间移植。
第 6 层:执行与编排层
职责:将计划转换为实际执行流(同步/异步),管理并发、重试、超时、补偿和人在回路交互。
输入输出:
- 输入:计划(任务序列)、技能调用
- 输出:执行结果、状态转换、通知、审计事件
这是引擎室。计划是静态描述;编排让它们在分布式、容易出错的世界中可靠地发生。
为什么编排非比寻常:智能体不是线性脚本。它们根据运行时条件分支、重试失败步骤、并行运行动作、等待外部事件(人工批准、API 回调)并从部分失败中恢复。
传统的基于有向无环图(DAG)的工作流(Airflow、Step Functions)无法处理这种复杂性。你需要支持循环流、条件分支和有状态恢复的编排框架。
实现模式:
- 状态机编排:
- 将执行建模为具有显式状态转换的有限状态机
- 示例状态:
pending → in_progress → awaiting_approval → completed | failed | compensating - 状态转换由事件触发(动作成功/失败、超时、人工输入)
- LangGraph、Temporal 和 AWS Step Functions(使用 Express Workflows)支持这一点
- 工作流模式:
- 顺序:按顺序执行步骤(例如,数据摄入 → 处理 → 存储)
- 并行:并发运行独立任务(例如,同时调用 3 个 API)
- 条件路由:根据运行时状态分支(if-then-else 逻辑)
- 反馈循环:带调整的重试(例如,如果第一次尝试失败则重新规划)
- 人在回路:暂停执行,请求批准,然后恢复
- 事件驱动架构:
- 使用消息队列(Kafka、RabbitMQ、SQS)解耦智能体
- 智能体 A 发布"任务完成"事件 → 智能体 B 订阅,开始下一步
- 好处:故障隔离、可扩展性、可重放能力
- 持久执行与检查点:
- 长时间运行的工作流需要持久化。如果编排器崩溃,它必须从最后一个检查点恢复
- 使用自动持久化状态的持久执行框架(Temporal、Durable Functions)
- 检查点策略:在每个动作完成后、分支决策之前保存状态
- 多智能体协调:
- 集中式(监督者模式):一个编排器向工作者智能体路由任务
- 去中心化(交接模式):智能体之间点对点传递控制(A → B → C)
- 分层:监督者智能体管理专家团队(管理者 → [智能体 1、智能体 2、智能体 3])
安全与可观测性:
- 分布式追踪:使用追踪 ID 对每个步骤进行埋点(OpenTelemetry span)
- 执行时间线可视化:显示哪个智能体做了什么,何时,为什么
- 重试/补偿日志:跟踪发生了多少次重试,补偿是否成功
- 服务水平协议(SLA)监控:如果执行超过延迟或成本预算则发出警报
框架比较(截至 2026 年 1 月):
| 框架 | 优势 | 最佳适用场景 |
|---|---|---|
| LangGraph | 基于图的状态机,构建于 LangChain 之上 | 复杂多步推理、循环工作流 |
| CrewAI | 基于角色的智能体、分层团队 | 多智能体协作、专业化角色分工 |
| AutoGen | 智能体间对话、灵活路由 | 研究、代码生成、辩论/共识模式 |
| Temporal | 持久化执行、容错工作流 | 长时间运行、关键任务流程 |
部署考虑:到 2026 年年中,57% 的组织部署多步骤工作流,16% 运行跨团队的跨职能智能体。编排复杂性是第一大扩展障碍。尽早投资可观测性和测试框架。
第 7 层:安全、对齐与治理层
职责:在所有层级强制执行策略、约束和道德护栏。实施输入/输出过滤、动作批准门控、冲突解决、人工覆盖和审计追踪。
输入输出:
- 输入:来自所有层的每个决策、动作请求和数据访问
- 输出:接受/拒绝信号、修改建议、升级触发器、审计日志
这是免疫系统,不是单个组件,而是贯穿所有层的横切关注点。没有它,智能体就是脱缰的野马。
为什么治理不能事后再考虑:在 2026 年 1 月,对智能体的监管压力正在加剧。GDPR、SOX、HIPAA、欧盟 AI 法案、NIST AI RMF —— 所有这些都要求可解释性、可审计性和人工监督。如果无法证明合规,就无法部署。
此外,自主系统会放大风险。智能体的一个错误决策可能级联成财务损失、数据泄露或声誉损害。
实现模式:
- 策略即代码:
- 使用声明性语言定义策略(Open Policy Agent 使用 Rego,AWS 使用 Cedar)
- 示例策略:"未经人工批准,任何智能体不得转账超过 5000 美元。"
- 策略进行版本控制、审计,并集中管理
- 输入/输出护栏:
- 输入过滤:阻止对抗性提示(越狱、提示注入)、个人可识别信息暴露、恶意负载
- 输出过滤:在执行动作之前检测幻觉、有毒内容、策略违规
- 工具:NeMo Guardrails、Guardrails AI、LLamaGuard
- 风险分级批准门控:
- 低风险动作:完全自主(只读查询、草稿生成)
- 中等风险:监督自主(提交前预览、软性批准)
- 高风险:硬门控——需要人工批准,破坏性操作需要双重控制
- 人在回路(HITL):
- 当置信度低、动作影响范围大或模型出现分歧时 → 暂停并升级
- 实施用于紧急停止的"大红按钮"
- 提供操作员操作手册,用于干预、回滚、覆盖
- 审计与可解释性:
- 决策日志:捕获推理轨迹(为什么智能体选择动作 A 而不是 B)
- 不可变审计追踪:一次写入日志,保留 12 个月以上以满足合规要求
- 解释模式:按需提供智能体决策的理由("你为什么推荐 X?")
- 异常与漂移检测:
- 监控智能体行为是否偏离基线(异常工具调用、违规动作)
- 对行为漂移(模型输出随时间变化)发出警报
- 红队测试:定期探测漏洞(对抗性输入、权限提升)
安全与可观测性:
- 策略强制日志:哪些策略触发,哪些动作被阻止,为什么
- 误报/漏报跟踪:护栏是否过于严格(阻止有效动作)或过于宽松(让坏动作通过)?
- 升级指标:智能体需要人工干预的频率如何?
- 合规仪表板:SOC 2、GDPR、NIST 对齐状态
实际影响:麦肯锡报告称,拥有强大治理框架的组织部署 AI 的速度是那些仓促返工控制的组织的两倍。Payhawk 使用策略驱动的智能体化系统将安全调查时间减少了 80%。
合规框架(2026 年快照):
- GDPR(欧盟):数据最小化、被遗忘权、可解释性、同意管理
- NIST AI RMF(美国):可信度、透明度、问责制、公平性
- 欧盟 AI 法案:基于风险的分类,高风险系统需要人工监督、合格评定
- SOC 2 Type 2:安全性、可用性、保密性、隐私控制
第 8 层:基础设施、可观测性与治理层
职责:提供运行时平台、数据/模型管理、持续集成/持续部署(CI/CD)、资源编排、成本控制、可观测性工具和治理自动化。
输入输出:
- 输入:来自所有层的指标、日志、追踪、模型版本、策略定义和账单数据
- 输出:警报、仪表板、合规报告、自动扩缩操作、回滚触发器
这是基础,其他一切都运行在其之上。如果做错了,你的智能体就是纸牌屋。
为什么基础设施是一等公民:与传统应用不同,智能体有独特的运维需求:
token 成本波动:单个失控循环就可能消耗数千美元
- 非确定性行为:相同输入,不同输出——调试是一场噩梦
- 多模型依赖:智能体调用 5 个以上模型(嵌入向量、规划 LLM、工具使用 LLM、重排序器)
- 长时间运行的工作流:执行跨时数/天,需要持久状态
实现模式:
- 容器编排(Kubernetes):
- 将智能体部署为容器化服务(Docker)
- K8s 处理扩缩容、负载均衡、健康检查和滚动更新
- 使用 Helm 图表进行可重复部署
- 无服务器部署(FaaS):
- 对于事件驱动的智能体,部署为 AWS Lambda、Azure Functions、Google Cloud Run
- 好处:自动扩缩、按调用付费、无需基础设施管理
- 权衡:冷启动、执行时间限制
- 模型托管与管理(MLOps):
- 模型注册表:对所有模型(嵌入向量、LLM、微调模型)进行版本控制、标记、追踪谱系
- A/B 测试:将流量路由到不同模型版本(例如,90% GPT-4,10% GPT-4-turbo)
- 模型监控:按模型跟踪漂移、准确性、延迟
- 回滚策略:如果新模型质量下降,自动回滚到先前版本
- 可观测性栈(日志、指标、追踪):
- 日志:ELK(Elasticsearch-Logstash-Kibana)、Splunk、Loki
- 指标:Prometheus + Grafana 用于时间序列(延迟、吞吐量、错误率、token 使用)
- 分布式追踪:OpenTelemetry、Jaeger、Zipkin(跨智能体、工具、模型追踪执行)
- 智能体特定可观测性:AgentOps、LangSmith、Arize AI、Galileo
- 成本管理(AI 的 FinOps):
- token 追踪:按智能体、按用户、按工作流监控 token 消耗
- 预算警报:当支出超过阈值(小时/天/月)时触发
- 成本归属:用成本中心标记智能体/工作流,用于退款
- 优化:缓存嵌入向量,对低风险任务使用更便宜的模型,实施速率限制
- 自主 FinOps 智能体:自动优化云支出的 AI 系统(调整资源大小、安排关闭)
- 密钥与凭证管理:
- 永远不要硬编码 API 密钥。使用密钥库(HashiCorp Vault、AWS Secrets Manager、Azure Key Vault)
- 自动轮换密钥(30-90 天周期)
- 实施最小权限访问(每个智能体/工具获得范围化凭证)
- 数据治理与隐私:
- 数据谱系:跟踪从源头 → 智能体 → 动作的数据流
- 保留策略:N 天后自动删除个人可识别信息(GDPR 合规)
- 加密:静态(S3、数据库)和传输中(TLS)
- 多租户隔离:防止跨客户数据泄露
安全与可观测性:
- 统一仪表板:所有智能体的单一控制面板(成本、性能、质量、合规性)
- 服务水平目标/服务水平指标(SLO/SLI)跟踪:定义服务水平目标(例如,95% 的请求延迟 < 2 秒),测量服务水平指标
- 事件响应:针对常见故障(模型超时、速率限制超出)的自动化运行手册
- 容量规划:根据使用趋势预测资源需求
可观测性平台(2026 年领导者):
- LangSmith:专为 LangChain/LangGraph 智能体构建,追踪、评估、数据集
- Arize AI:模型监控、漂移检测、可解释性
- AgentSight:基于 eBPF 的多智能体系统追踪,专注安全
- Datadog / New Relic / Dynatrace:带 AI/ML 扩展的通用应用性能监控
FinOps 快照(2026 年 1 月):
- 到 2030 年,智能体化 AI 将占全球 IT 支出的 26% 以上,达到 1.3 万亿美元
- 早期 FinOps 采用者报告称,通过自主优化,云成本降低了 40%
- 关键成本驱动因素:LLM API 调用(60%)、向量数据库查询(20%)、计算基础设施(15%)、数据传输(5%)
端到端执行流程:整合所有层
让我们跟踪一个真实工作流,经过所有 8 层。场景:客户通过聊天提交复杂服务请求。
步骤 1:感知(第 1 层)→ 用户消息通过 webhook 到达。感知层验证模式,提取意图("我需要升级订阅并添加用户席位"),并生成标准化观测事件。
步骤 2:表示(第 2 层)→ 观测被嵌入到向量空间,语义搜索检索相关过去对话("用户之前询问过定价层级"),短期记忆缓存存储当前会话状态。
步骤 3:世界模型(第 3 层)→ 智能体查询知识图谱:用户当前计划(Pro 层级)、已用席位(8/10)、账单状态(活跃)、公司政策(如果升级后年度费用 > 1000 美元则需要批准)。
步骤 4:规划(第 4 层)→ 分层任务网络规划器将目标分解为子任务:检查资格、计算价格差异、生成升级提案、请求批准。规划器识别约束:需要经理批准(高价值变更)。
步骤 5:技能(第 5 层)→ 规划层调用工具:get_subscription_details(user_id)、calculate_upgrade_cost(current_plan, target_plan, seat_delta)、create_approval_request(manager_email, proposal)。
步骤 6:执行(第 6 层)→ 编排器顺序执行计划:调用 Stripe API → 成功 → 调用内部批准 API → 暂停执行,等待批准事件。人事经理通过 Slack 批准。编排器恢复 → 调用 apply_upgrade() → 成功。
步骤 7:安全(第 7 层)→ 在执行 apply_upgrade() 之前,治理层检查:智能体有权限吗?(是的,通过基于角色的访问控制)。这违反支出限制吗?(不,低于 5000 美元阈值)。这是敏感动作吗?(是的,金融交易 → 记录到审计追踪)。护栏批准动作。
步骤 8:基础设施(第 8 层)→ 在整个执行过程中,OpenTelemetry 跨度跟踪延迟(总计:8.2 秒)、token 使用(3200 token)和成本(0.14 美元)。日志流向 ELK。指标推送到 Prometheus。触发警报:"批准延迟超出服务水平协议(>5 分钟)"。FinOps 仪表板更新:此用户支出增加 0.14 美元。
最终输出:用户收到包含发票链接的确认消息。智能体记忆存储交互摘要供将来参考。审计日志包含完整追踪(符合 SOC 2 要求)。
设计原则与工程最佳实践
1. 模块化是必须的
每一层可独立部署,使用清晰的 API 契约(OpenAPI、gRPC),避免紧耦合。好处:更容易测试、更快迭代、团队自治。
2. 可观测性是一等公民
从第一天就进行埋点,每一层都会发出结构化日志、指标和追踪,在投入生产之前构建仪表板。你无法调试看不到的东西。
3. 从确定性开始,逐步增加自主性
第一天不要完全自主。从结构化工作流(第 6 层编排)开始,验证可靠性,然后逐步赋予智能体更多决策权(第 4 层规划)。高风险动作最初始终需要人工批准。
4. 为失败设计
智能体总会失败。API 会超时,模型会产生幻觉,计划会偏离轨道。实施重试、补偿、回滚和升级路径,使用幂等动作,积极设置检查点状态。
5. 从第一天开始进行成本治理
token 成本可能螺旋上升。实施预算上限、每用户配额和每次请求成本跟踪。在可接受的地方使用更便宜的模型(嵌入向量、简单分类)。积极缓存。
6. 无处不在的最小权限
每个组件(智能体、工具、数据库)都只获得所需的最小权限。使用服务账户、轮换凭证和审计访问,限制出问题时的影响范围。
7. 自主性与组件分开测试
单元测试验证单个工具工作。集成测试验证编排。但还需要行为测试:智能体能否可靠实现目标?使用评估框架(LangSmith、Phoenix、Galileo)测量成功率、准确性和延迟。
8. 所有内容都有版本控制
模型、提示词、工具、策略、数据模式 —— 全部进行版本控制。使用语义化版本控制。标记生产部署。这支持回滚和 A/B 测试。
每层典型指标与 KPI
| 层级 | 关键指标 |
|---|---|
| 1. 感知层 | 输入延迟(p50/p99)、模式验证错误数、畸形事件百分比、数据摄取吞吐量 |
| 2. 表示层 | 检索 precision@k / recall@k、嵌入延迟、向量数据库查询时间、内存缓存命中率 |
| 3. 世界模型层 | 状态一致性错误、约束违反率、置信度分数分布、知识图谱更新延迟 |
| 4. 规划层 | 计划生成时间、计划成功率、重新规划频率、人工审批率 |
| 5. 技能层 | 工具调用成功率、工具延迟(按工具分类)、幂等性违反次数、补偿触发率 |
| 6. 执行层 | 工作流完成率、重试次数、补偿执行时间、人工介入率、SLA 达标率 |
| 7. 安全层 | 策略违反率、护栏拦截率、误报/漏报率、审计日志覆盖率、升级频率 |
| 8. 基础设施层 | 每个请求总成本、每个智能体 token 用量、延迟 p50/p95/p99、错误率、可用性百分比、模型漂移告警 |
常见反模式及如何避免
❌ 单体 LLM 即智能体
症状:整个系统是一个带有工具调用的巨型提示词,调试困难,成本爆炸。
修复:分解为层。使用规划层进行策略,执行层进行编排,技能层用于工具。
❌ 内存无限增长
症状:向量数据库无限增长,查询延迟增加,成本飙升。
修复:实施带衰减、总结和归档策略的分层记忆。
❌ 没有约束强制执行
症状:智能体违反业务规则、合规政策和预算限制。
修复:从一开始就构建世界模型(第 3 层)和治理层(第 7 层)。
❌ 静默失败
症状:智能体失败,但没有警报。用户几天后才投诉。
修复:实施全面可观测性(第 8 层):分布式追踪、结构化日志记录和异常警报。
❌ 硬编码提示词与工具
症状:每次更改都需要代码部署,测试被发布周期阻塞。
修复:外部化提示词(LangSmith 提示中心),使用工具注册表,启用 A/B 测试。
❌ 没有人工覆盖
症状:智能体做出错误决策。无法停止或覆盖。
修复:实施紧急按钮、高风险动作的批准门控和操作员操作手册。
快速实施清单
构建 8 层系统听起来令人生畏,不过可以从这里开始:
第一阶段:基础(第 1-2 周)
- ✅ 定义统一事件模式(第 1 层)
- ✅ 设置向量数据库 + 会话缓存(第 2 层)
- ✅ 实现策略即代码 + 基于角色的访问控制(第 7 层)
第二阶段:核心工作流(第 3-4 周)
- ✅ 使用适当契约构建第一个技能(第 5 层)
- ✅ 为领域实现世界模型(第 3 层)
- ✅ 使用状态机设置基本编排(第 6 层)
第三阶段:规划与可观测性(第 5-6 周)
- ✅ 添加带约束检查的分层规划(第 4 层)
- ✅ 部署可观测性栈(日志 + 指标 + 追踪)(第 8 层)
- ✅ 设置成本跟踪和预算警报(第 8 层)
第四阶段:扩展与优化(持续进行)
- 添加更多技能和工具发现
- 通过战略性遗忘优化记忆
- 根据生产经验优化治理
竞争优势:为什么架构现在至关重要
在 AI 领域,人们很容易被最新的模型排行榜迷惑,认为更大的模型总是更好。但在企业环境中,架构 > 模型能力。
一个设计良好的 8 层架构带来的竞争优势:
更快的迭代速度:模块化架构意味着独立团队可以并行工作在不同层上。数据团队可以改进记忆层,工程团队可以优化编排,而不会互相阻塞。
更强的合规性:内置治理、审计和可控性意味着你可以在受监管的行业中部署智能体——医疗、金融、政府——而那些无架构的单体智能体做不到。
更低的总体拥有成本:合理的分层让你可以对不同任务使用不同模型——简单任务使用较小的模型,复杂任务使用较大的模型。成本会下降 30-50%,而不会损失能力。
更好的可扩展性:当你的智能体从 10 个用户增长到 10,000 个用户,架构化系统可以水平扩展,而单体智能体会在负载下崩溃。
那些今天投资正确架构的组织,将会在明年拥有显著的竞争优势。当对手还在修复生产环境中不断出现的问题时,你已经在发布新功能了。
结论:从原型到生产系统
智能体化 AI 不再是研究实验。它正在快速成为企业应用程序的标准构建块。
但从"令人印象深刻的演示"到"生产级系统"的跨越,不是通过更大的模型就能实现的。它需要严谨的工程设计:清晰的边界、模块化设计、适当的治理和扎实的基础设施。
这正是 8 层架构带来的 —— 一个经过深思熟虑的框架,将智能体从脆弱的原型转变为可靠的生产系统:
- 感知层确保干净的输入
- 表示/记忆层提供持久化知识
- 世界模型让智能体能够推理约束
- 规划层将目标分解为可执行步骤
- 技能层封装可靠的工具能力
- 编排层可靠地执行复杂工作流
- 安全/治理层保持合规和安全
- 基础设施层提供可观测性和成本控制
无论你是刚刚开始构建第一个企业智能体,还是正在将现有原型改造为产品,这个框架都能帮你理清思路,聚焦在正确的事情上。
问题不在于是否需要构建智能体 —— 问题在于能否构建得足够好。那些掌握了架构的人,将定义下一代企业软件。